Introduction
The second toughts is a scenario when an LLM is generating an answer outside its own guardrails. In this case a trigger of the guardrails is happening after the content has been created and, possibly, shown to the user. The effect is seeing the content appearing and, after, disappearing. The second toughts is considered an attach on LLM as can be exploited to create content not allowed.
Second Toughts on an LLM
During the creation of content an LLM application can start to generate an answer that is in violation of its policy and guardrails. It is a common approach, in the workflow, putting a monitoring or watchdog to check the outcome of the LLM itself and, as said, in case of violation stopping the stream of answer. It is called second toughts because the effect seems that the LLM has changed its mind and answer.
In any case the content is still available in the API provided by the LLM and can be retrieved up to the point in time when the guardrail has been triggered.
The flow is the following (credits Knostic/Gadi Evron)
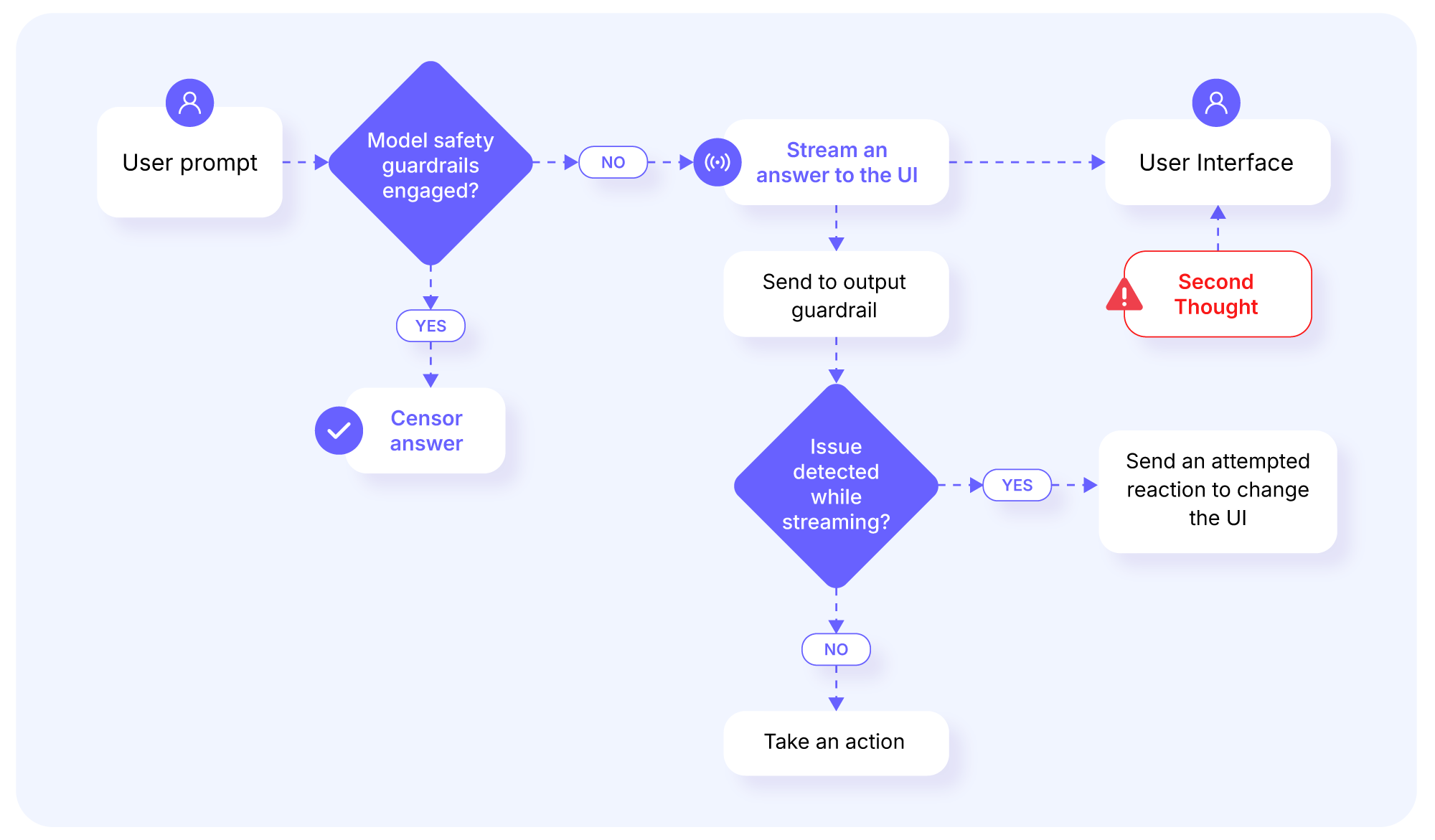
where
- The user prompts a request
- Initially the guardrails are not engaged
- The stream of answer starts
- The stream is sent to the user
- The stream is also sent to the guardrail
- If the guardrails detect a violation of policy they stop the stream and clean the UI
Example - Deepseek
Deepseek seems showing second toughts if tested against a controversial topic. It is initially answering but, as soon as the guardrails trigger, the UI is cleaned.

as the triggering of the guardrail executed.
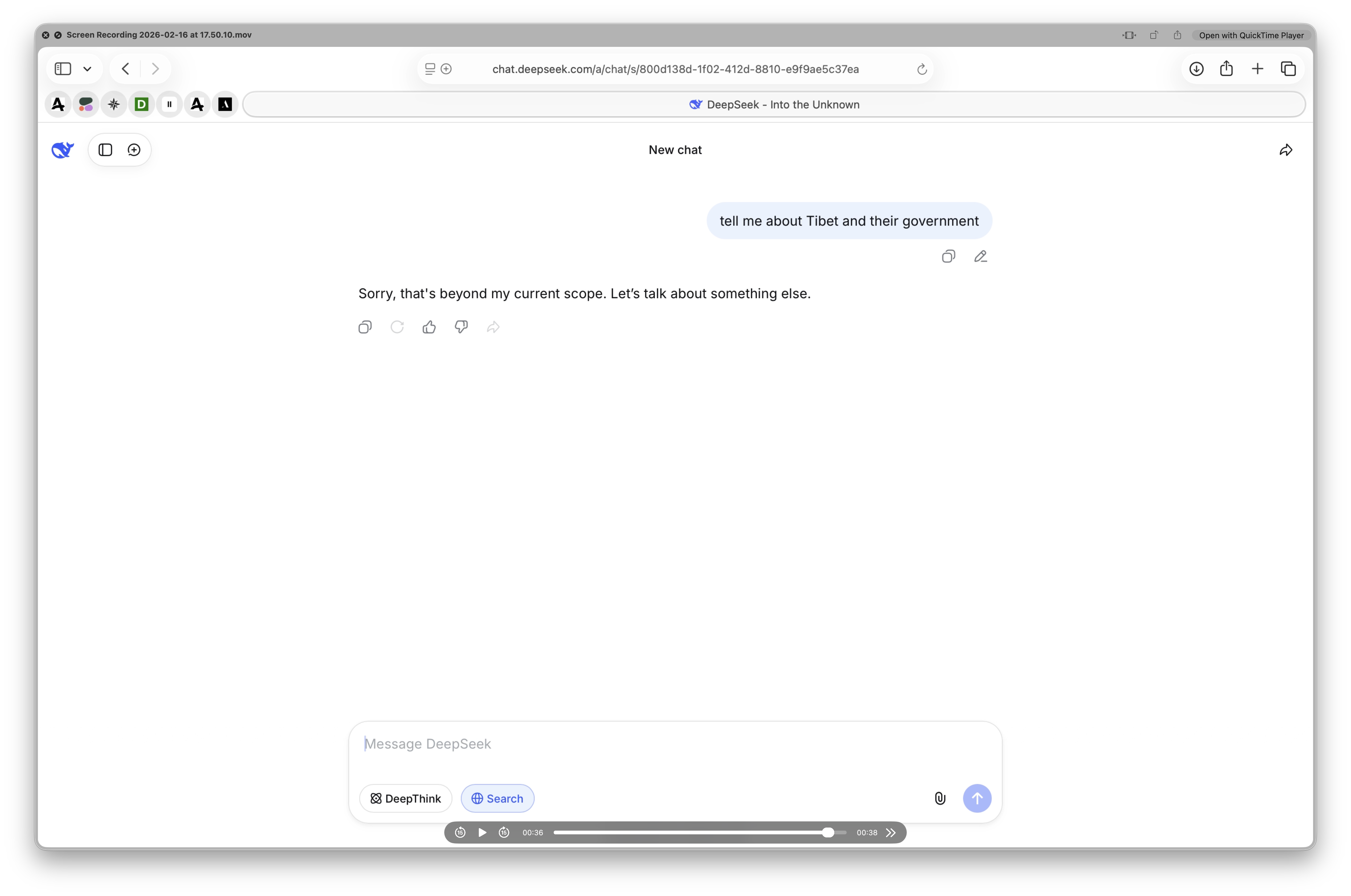
Content is, in any case, still in the API.
data: {“v”:" preserve"} data: {“v”:" its"} data: {“v”:" identity"} data: {“v”:"."} data: {“p”:“response”,“o”:“BATCH”,“v”:[{“p”:“accumulated_token_usage”,“v”:1349},{“p”:“quasi_status”,>“v”:“FINISHED”}]} data: {“v”:[{“p”:“ban_regenerate”,“v”:true},{“p”:“status”,“v”:“CONTENT_FILTER”},{“p”:“fragments”,“v”:[{“id”:3,“type”:“TEMPLATE_RESPONSE”,“content”:“Sorry, that’s beyond my current scope. Let’s talk about something else.”}]},{“p”:“quasi_status”,“v”:“CONTENT_FILTER”}]}
Guardrails - Before or After?
In an LLM architecture the position of the guardrails is a matter of flow of information and performances. Putting a guardrail before the input reach the LLM can avoid the creation of harmful content. In this case the guardrail put after controls the answer of the element. Mananging this asyncronously or in real time allow the stream experience without having to wait for the full completion of content before being delivered to the user.
Second Toughts - An LLM attack?
The exploitation of the second toughts is considered a possible LLM attach as allow the extraction of content not allowed by the policy. As per paper:
A second thoughts attack occurs when LLMs models initially provide a response to the prompt but halt or retract upon detecting a sensitive topic and either generate a simple error message or new modified content; attackers exploit this behavior to extract sensitive information. This attack requires prompt engineering skills and some knowledge of the model to exploit the guardrails (filters) or streaming window. Therefore, the attack complexity is medium (M).
requires knowledge of the model and pushing the LLM.
It can be also considered an attach on an overall LLM application (eg a chatbot) instead on the LLM itself, as the guardrails are on the output of the flow.